[예약 구매 프로젝트] 캐싱 전략 적용
예약 구매 프로젝트
지난달 말부터 대규모 동시 요청 상황을 가정한 예약 구매 프로젝트를 진행 중입니다. 예약 구매라는 말이 와닿지 않는다면 온라인 티켓팅, 한정판 도서/앨범 구매 등을 떠올려보면 좋습니다. 프로젝트 요구 사항에 따르면 동시 1만 건 요청 시 데이터 정합성이 유지돼야 하고 사용자 경험도 일정 수준 이상으로 확보해야 합니다. 이번 글에선 사용자 경험, 즉 응답 속도 개선을 위해 어떤 방법을 선택했는지 적어보려 합니다.
아래는 기본 기능 구현 때 짜놓은 주문 로직 시퀀스입니다.

1. 클라이언트의 주문 요청이 들어옵니다.
2. 서버는 주문 목록의 상품 재고를 DB에서 확인합니다.
3. DB는 재고 정보를 반환합니다.
4. 재고가 충분하다면 주문 수량만큼 재고를 차감하고 DB에 반영합니다.
5. 반영에 성공하면 결과를 받고
6. 클라이언트에게 주문 성공 응답을 전달합니다.
재고를 확인하고 응답하는 과정은 언뜻 보면 문제가 없어 보이지만, 문제는 동시에 많은 요청이 들어오는 상황을 가정하고 대비해야 한다는 것입니다. Spring Boot 프로젝트에서 내장 톰캣을 사용할 경우 Apache Tomcat의 기본 스레드 풀 maxThreads 값은 200으로 설정되어 있습니다. 10000건의 주문과 비교하면 매우 적은 수고, 만약 요청 처리 속도가 느리다면 그만큼 많은 요청이 연결 단계에서 실패하거나 응답 속도가 늦어질 겁니다. 컴퓨팅 자원이 한정되어 있기 때문에 마냥 스레드풀 사이즈를 늘릴 수 도 없습니다. 저는 상품 재고를 Redis에 캐싱하고 이를 활용하기로 했습니다.

요청이 들어오면 서버는 Cache Storage에서 데이터를 찾습니다. Cache Hit가 발생하면 서버는 캐시 스토리지의 재고를 차감하고 클라이언트에게 응답하게 됩니다.
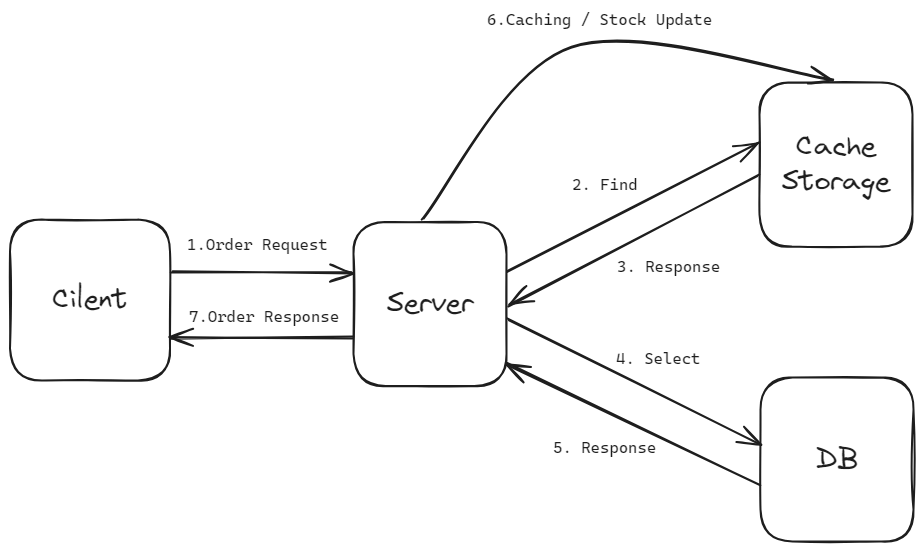
이번엔 스토리지에서 캐시 데이터를 찾지 못한 경우(Cache Miss)입니다. 서버는 DB에서 해당 값을 찾아 캐시 스토리지에 업데이트하고, 클라이언트에게 결과를 반환합니다. 이처럼 캐시 스토리지를 먼저 확인하고, 값을 찾지 못하면 DB를 통해 값을 찾고 캐시하여 사용하는 읽기 전략을 Look Aside 패턴이라고 부릅니다.
관계형 DB와 In Memory DB의 응답 속도 차이는 엄청나기 때문에, 우리는 클라이언트의 사용 경험이 크게 향상될 거라고 기대할 수 있습니다.
다만 위 시퀀스의 경우 약간의 문제가 있습니다. 주문 시 캐시 스토리지의 값만 차감하고 있기 때문에 DB와 데이터 불일치가 생기고, 이를 동기화하기 전에 모종의 이유로 캐시 스토리지가 다운되게 된다면 데이터가 유실될 수 있습니다. 주문 데이터 유실은 심각한 문제를 야기할 수 있고 이에 대한 대책을 마련해야 합니다.
여기서 쓰기 전략에 대한 고민이 시작됩니다.

먼저 캐시 스토리지의 데이터를 스케쥴링을 통해 일정 시간마다 DB에 동기화시키는 Write Back 패턴이 있습니다. DB접근을 최소화하기 때문에 성능이 우수할 거라고 예상할 수 있습니다. 대규모 트래픽 처리에 있어서 성능 상 이점을 가질 수 있겠으나, 위에 적었듯 주문 정보는 유실되면 비즈니스에서 치명적일 수 있습니다. 그렇다면 데이터를 항상 동기화할 순 없을까요?
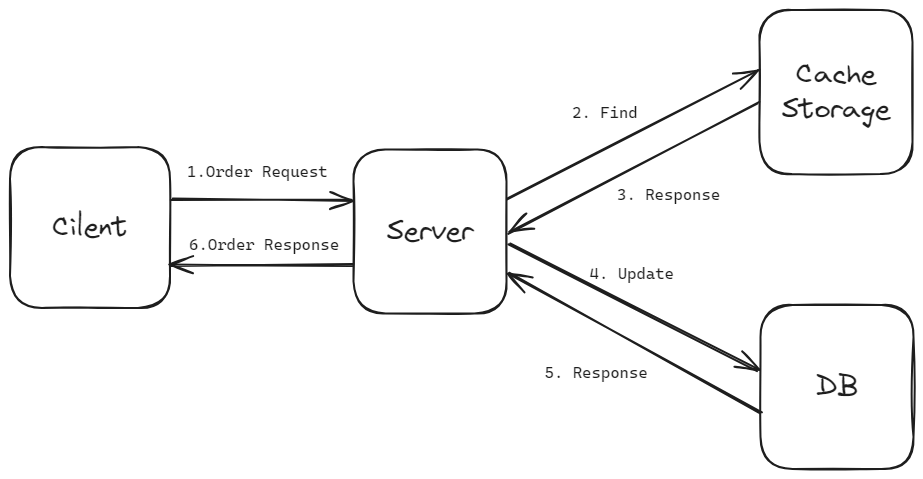
캐시 스토리지에서 바로 DB에 동기화하는 Write Through 패턴을 선택할 수도 있지만, 저는 해당 작업의 주도권을 서버에 두었습니다. 위 방법을 선택하면 캐시 스토리지의 데이터와 DB 데이터를 매 요청마다 동기화하고 있기 때문에 데이터 정합성에서 크게 유리합니다.
Write Back 패턴보다는 성능이 다소 떨어지겠지만 캐시 데이터를 활용한다는 점에서 기존 방식보다 높은 성능을 기대할 수 있을 것처럼 보입니다.
다만 위 시퀀스에서 정말로 캐싱의 이점을 살리고 싶다면 반드시 수정해야 할 부분이 있습니다. 바로 4, 5번 시퀀스입니다. 2,3번 과정에서 캐싱을 통해 읽기와 쓰기 속도를 향상 시켰는데, 그걸 다시 DB에 반영하고 응답을 기다려야 한다면 앞의 과정이 무의미해집니다. 따라서 약간의 변형을 통해 캐싱의 이점을 살려줘야 합니다. Update 쿼리를 비동기 처리해 봅니다.

3번까지의 시퀀스는 동일합니다. 다만 4번 요청을 Async를 적용해 응답을 기다리지 않고 처리하도록 변경했습니다. 이렇게 하면 사실상 모든 주문이 보조 기억장치를 거치지 않고 메모리 위에서 일어나기 때문에 캐싱 처리의 이점을 살릴 수 있습니다.
@Transactional
public List<OrderDetailEntity> addOrder(OrderEntity orderEntity, List<OrderDetailRequestDto> orderDetailRequstDtoList) {
List<OrderDetailEntity> orderDetailEntities = new ArrayList<>();
for (OrderDetailRequestDto orderDetailRequestDto : orderDetailRequstDtoList) {
Long productId = orderDetailRequestDto.getProductId();
// cache miss 시 캐싱
checkCache(productId);
Long stock = stockService.getStockInRedis(productId);
Long amount = orderDetailRequestDto.getAmount();
validateOrderRequest(stock, amount);
// redis 재고 update
stockService.updateStockInRedis(productId, amount);
// 비동기 sql query 실행
stockService.updateStockAfterOrder(productId, amount);
ProductDto productDto = productService.getProduct(productId);
orderDetailEntities.add(
OrderDetailEntity.builder().orderEntity(orderEntity)
.productEntity(productDto.toEntity())
.amount(orderDetailRequestDto.getAmount()).build()
);
}
return orderDetailEntities;
}
주문 상세 추가 로직 내부에서
private void checkCache(Long productId) {
if (!stockService.isCached(productId)){
StockEntity stockEntity = stockService.getStockByProductId(productId);
if (stockEntity.getAmount() > 0){
stockService.redisCache(productId);
}else{
throw new OrderException(OrderResponseMessage.OUT_OF_STOCK);
}
}
}
캐싱 여부를 확인하는 메서드가 호출됩니다. 만약 캐시 데이터가 없다면 캐싱을 진행합니다.
@Async
@Transactional
public void updateStockAfterOrder(Long stockId, Long amount){
stockRepository.updateStockAfterOrder(stockId, amount);
}
Async 어노테이션을 사용해서 재고 차감을 비동기 처리하고
@Async
public void orderDetailSaveAll(List<OrderDetailEntity> orderDetailEntities){
orderDetailRepository.saveAll(orderDetailEntities);
}
주문 상세를 저장하는 메서드 또한 동일하게 처리했습니다.
위 과정을 적용한 뒤 tps와 최대 응답 시간이 기존 방식에서 9배가량 향상 되었습니다.
사실 DB -> Redis 사용으로 전환한 것 치고는 큰 폭의 성능 향상은 아니라고 느껴지는데, 이는 주문 로직에서 발생하는 조회가 복잡하게 얽혀있기 때문인 것으로 보입니다. 현재 캐싱 처리한 건 재고 차감과 일부 insert 로직뿐이고, 내부에서 일어나는 select 작업에 대한 캐싱이나 최적화는 진행하지 않은 상태입니다. 즉 쓰기 작업 일부만 최적화를 진행한 상태인데도 성능 개선이 눈에 띄게 일어난 걸 보면 되려 개선하는 맛이 쏠쏠하다고 할 수 있습니다.
다만 비동기 처리를 함으로써 주문이 완료되지 않고 취소되어야 하는 경우( ex - 결제 실패), 동기적으로 처리할 때 RollBack 한 번으로 주문 데이터가 처리되던 것과 달리 별도로 재고 복구 로직을 만들어줘야 합니다. 성능과 개발 당사자의 노고를 바꾼 샘이라고 할 수 있습니다.
아무렴 좋은 프로젝트가 될 수만 있다면야 뭘 못하겠냐만은...
공부도, 개발도 할 게 많은 초보 개발자의 밤은 오늘도 짧으려나 싶습니다.