더 더 빠르게, 최적화는 끝이 없다
지난 캐싱 전략 글에서 조회 캐싱까진 진행하지 못해서 아쉽다는 말을 포스팅 말미에 적었었지요. 이전엔 DB write 작업을 효율적으로 하기 위한 캐싱을 적용했다면, 오늘은 Read에 대한 캐싱을 적용하고 성능이 얼마나 개선되었는지 말해보려 합니다. 재고 캐싱에 대한 글은 아래 링크로!
[예약 구매 프로젝트] 캐싱 전략 적용
예약 구매 프로젝트지난달 말부터 대규모 동시 요청 상황을 가정한 예약 구매 프로젝트를 진행 중입니다. 예약 구매라는 말이 와닿지 않는다면 온라인 티켓팅, 한정판 도서/앨범 구매 등을 떠올
dooduz.tistory.com
public ProductDto getProduct(Long productId) {
String key = String.valueOf(productId);
// 캐시 데이터가 있다면 꺼내서 리턴
if (isCached(key)) {
return (ProductDto) productRedisRepository.find(key);
}
ProductEntity productEntity = getProductEntity(productId);
// 공개되지 않았거나 숨김 처리된 상품이면 throw
ProductStatus productStatus = productEntity.getProductStatus();
if (productStatus == ProductStatus.NOT_PUBLISHED || productStatus == ProductStatus.SUSPENDED_SALE) {
throw new ProductException(ProductMessage.NOT_FOUND_PRODUCT);
}
ProductDto productDto = getProductDto(productEntity);
productDto.setAmount(0L);
// DB에서 가져온 데이터를 캐싱
productRedisRepository.cache(key, productDto);
return productDto;
}
추가로 캐싱이 된 부분은 상품 가격 정보를 찾기 위한 getProduct 메서드입니다. 기존엔 캐시 로직 없이 직접 DB에서 Entity를 가져와서 Dto로 반환하여 리턴했습니다. 현재는 캐시 데이터가 있다면 바로 데이터를 반환해 주고, 없다면 DB값을 읽어 캐싱하는 Look Aside 패턴이 적용된 상태입니다.
public void cache(String key, Object value){
redisTemplate.opsForValue().setIfAbsent(addPrefix(key), value, timeout);
redisTemplate.expire(addPrefix(key), timeout);
}
@Cacheable 어노테이션을 통해 좀 더 간편하게 캐시 할 수 있지만, 이번엔 redisTemplate의 기능을 사용해 직접 캐싱했습니다. opsForValue.set()을 사용하면 기존 캐시데이터가 있더라도 다시 데이터가 덮어 써지며 데이터 정합성이 깨질 수 있기 때문에 setIfAbsent 메서드를 사용했습니다. 평상시 조회를 위해서라기 보단 대규모 주문 상황에 대처하기 위한 캐싱이므로 TTL은 10분으로 비교적 짧게 설정했습니다.
위에 추가한 코드 몇 줄로 과연 얼만큼의 성능 향상이 일어났을까요? 확인을 위해 Jmeter로 테스트를 진행해 보았습니다. 모든 요청에 대한 ramp-up은 1로 진행했습니다.
조회 테스트
Non Caching
1. 스레드 1000개 - 루프 1 요청

APDEX 1, 최대 응답 시간 484ms, 초당 트랜잭션 777이 측정됐습니다. 단순 조회 요청 답게 1000건 정도의 동시 주문 요청은 거뜬해 보입니다.
2. 스레드 2000개 - 루프 15 요청

스레드가 2배, 루프가 15배로 늘어났습니다. APDEX 0.080, 최대 응답 시간 2342ms, 초당 트랜잭션 992가 측정됐습니다. 요청이 늘어나니 병목이 생기고 그에 따라 성능이 크게 저하된 모습입니다. 초당 트랜잭션은 되려 상승한 것처럼 보이지만, 사실 먼저 있던 1000건의 요청이 서버의 최대 처리량을 밑돌았기 때문에 최대 효율이 나오지 않은 것으로 생각하면 될 것 같습니다.

위 지표에서 KO로 기록된 17건에 대한 에러 내용입니다. Tomcat이 쌓이는 요청을 모두 받아내지 못해 connect에 실패하여 발생한 오류입니다.
Caching
1. 스레드 1000개 - 루프 5 요청

앞의 테스트에서 1000개 - 루프 1 요청 시 서버 리소스가 충분히 감당하는 모습이 있었기 때문에 루프를 5번으로 늘려주었습니다. 더미 데이터의 로그인 시퀀스 또한 추가했는데 이는 더미 데이터를 위한 별도 요청으로 처리되었기 때문에 성능과 무관한 요청이라고 봐도 좋을 것 같습니다. 조회 요청에 대한 결과만 보면 APDEX 0.992, 최대 응답 시간 665ms, 초당 트랜잭션 1285가 측정됐습니다. 캐시 하지 않고 진행한 첫 번째 요청의 데이터가 지표상으론 더 좋지만, 요청이 5배 더 많다는 걸 감안해야 합니다. 요청을 더 늘려 보겠습니다.
2. 스레드 2000개 - 루프 15 요청
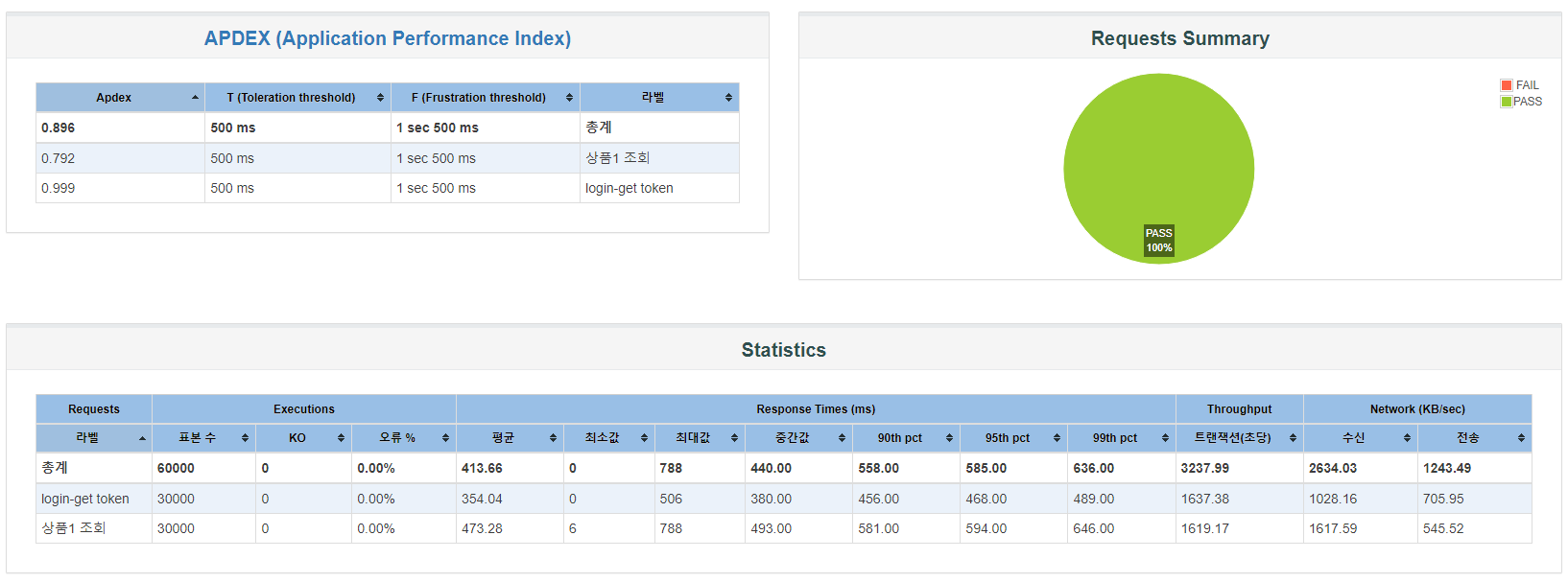
요청이 많아지니 캐시의 효과가 확실히 드러나는 게 보입니다. 캐시 전 0.080이었던 APDEX가 0.792 선을 지켜냈고, 최대 응답 시간 788ms, 초당 트랜잭션 1600을 기록했습니다. 확실한 성능 개선을 확인했으니, 이번엔 주문 테스트까지 진행해 보겠습니다.
주문 테스트
모든 테스트는 스레드 1000 - 루프 5 요청과 상품 4종을 구매하는 조건으로 진행되었습니다.
Non Caching(Pessimistic Lock)
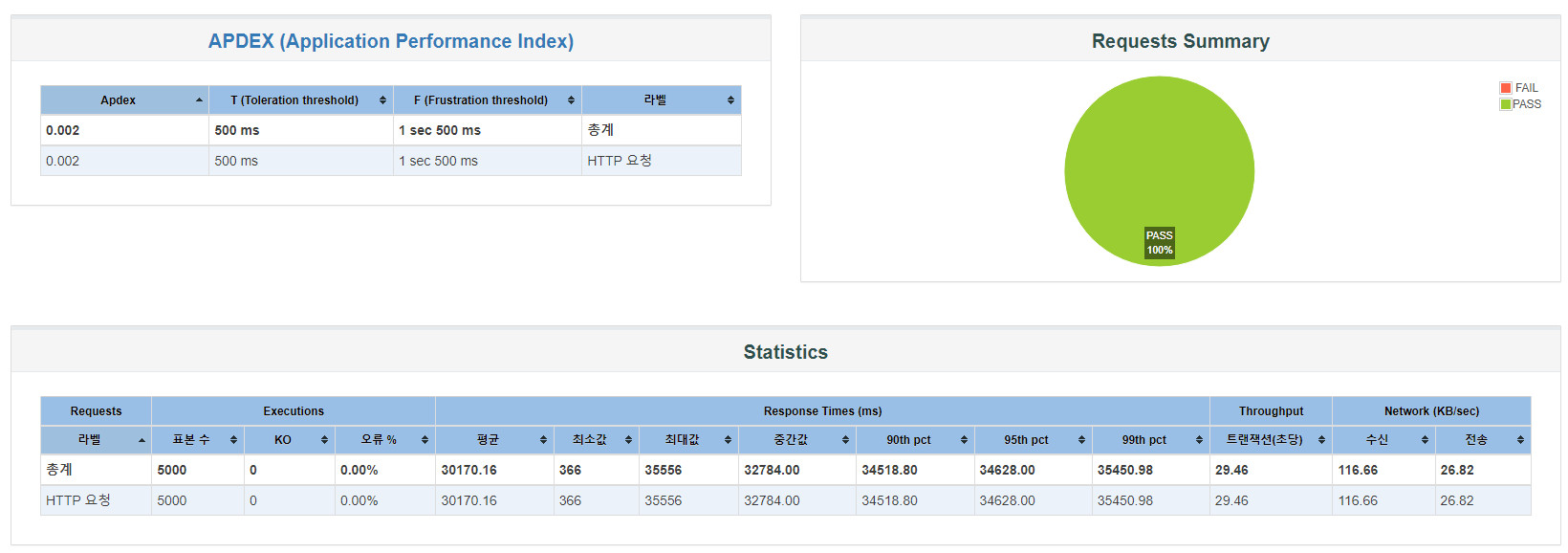
먼저 재고, 상품 상세 모두 캐싱되지 않았을 때의 요청입니다. 지표가 가히 절망적이라고 할 수 있습니다. APDEX 0.002, 최대 응답 시간 35556ms, 초당 트랜잭션 29.46을 기록했습니다. 반드시 개선이 필요한 수치입니다.
재고 Caching 적용(Redisson Lock)
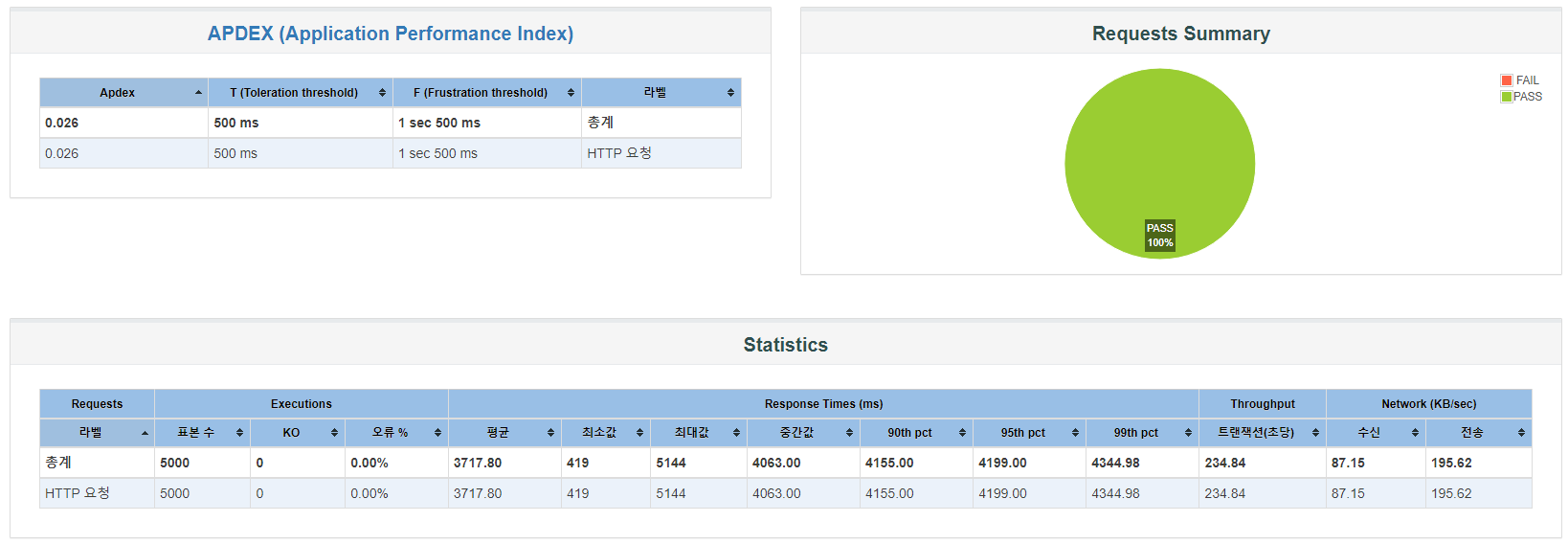
다음은 재고 캐싱만 진행한 경우입니다. APDEX 0.026, 최대 응답 시간 5144ms, 초당 트랜잭션 234가 기록됐습니다. APDEX는 여전히 낮지만, 응답 시간과 트랜잭션에선 거의 7~9배에 가까운 개선이 일어났습니다. 마지막으로 조회 캐싱까지 진행한 경우를 살펴보겠습니다.
스레드 1000 - 루프 5 요청

마지막은 상품을 조회하고, 장바구니에 담고, 주문하는 플로우로 테스트를 진행했습니다. 주문에서 발생한 20%가량의 KO는 의도된 것으로, 테스트 시나리오 요구사항 결제 20% 실패를 반영한 내용입니다. 테스트 시나리오가 다르므로 APDEX나 트랜잭션에 대한 정량적 비교는 어려울 수 있으나, 주문 시 최대 응답 시간 1478ms로 크게 개선된 것을 볼 수 있습니다. 재고 캐싱만 했을 때보다 3배 이상 빨라진 거죠.
기존에 매 주문마다 가격 조회, 하위 엔티티 생성을 위해 발생하던 product에 대한 select 쿼리 실행이 일어나지 않으니 성능이 더욱 상승했다고 보면 좋을 것 같습니다. 캐싱 데이터를 가져오는게 쿼리 실행보다 단순 조회 속도가 빠를 뿐더러, 주문 상황에선 DB-캐시 간 데이터 동기화를 위해 실행되는 Update쿼리, 주문 생성을 위한 Insert 쿼리와 함께 한정된 커넥션 풀을 사용해야 하기 때문에 단순 조회 요청만 쏟아질 때보다 속도가 느릴 수 밖에 없으니까요.
최종적으로 캐싱 적용 전의 속도 35000ms에서 캐싱 후 1500ms로 23배에 가까운 성능 상승이 일어났음을 볼 수 있습니다. 모든 테스트가 로컬에서 진행되었기 때문에 수치를 실제 서비스 상황에 대입하여 생각할 순 없겠지만, 동일 환경에서의 성능 상승은 확실히 증명됐다고 봐도 좋을 것 같습니다.
'Backend > Spring' 카테고리의 다른 글
| [예약 구매 프로젝트] 가상 스레드 적용 (0) | 2024.08.06 |
|---|---|
| [예약 구매 프로젝트] Test Code (0) | 2024.07.30 |
| [Spring Security] Session vs Token (0) | 2024.07.25 |
| [예약 구매 프로젝트] 동시 주문 요청 처리 (0) | 2024.07.24 |
| [예약 구매 프로젝트] 캐싱 전략 적용 (4) | 2024.07.23 |



