더 많은 요청을 견딜 수 있게 하기
이전 포스팅에서 캐싱 전략을 사용해 동시성과 성능 개선을 거쳤지만, 여전히 남아있는 문제가 있었습니다. 바로 처리 가능한 동시 요청 수에 대한 것이었는데요. 여태까지 진행한 대부분의 테스트는 스레드 1000개 x 루프 5번을 기준으로 진행했습니다. 한 번에 5000개의 스레드를 사용하지 않은 이유는 단순했습니다. 안정성이 보장되는 요청의 개수가 1000개였기 때문이죠. 제 목표는 10000개의 요청을 한 번에 받아내는 것이었고, 2000개 요청만 진행돼도 종종 HttpHostConnectException이 발생하는 기존 성능은 목표에 한참 못 미치는 것이었습니다.
요청 처리 속도가 빨라질수록 더 많은 요청을 받아낼 수 있었기 때문에, 조금이라도 성능을 개선하고자 Java 21에서 릴리즈 된 가상 스레드를 도입해 보기로 했습니다. 주문 로직에서 Redis나 DB에 대한 많은 I/O가 발생하고 있었기 때문에 무조건적인 성능 향상을 기대한 것은 아니었습니다. 다만 목표를 위해 뭐 하나라도 더 시도해 본다는 느낌이었죠.
포스팅을 진행하기에 앞서 가상 스레드에 대해 알게 된 내용에 대한 포스팅과, 적용 전의 성능에 대한 포스팅입니다.
Virtual Thread
신기술이란...Java 21부터 정식 릴리즈된 가상 스레드에 대해 알아보려고 합니다. 우아한 테크 채널의 발표 영상과 우아한 기술 블로그의 글을 많이 참조했습니다. 기술적으로 정확한 정보를 전달
dooduz.tistory.com
[예약 구매 프로젝트] 상품 조회 캐싱 추가 적용 - 성능 테스트
더 더 빠르게, 최적화는 끝이 없다지난 캐싱 전략 글에서 조회 캐싱까진 진행하지 못해서 아쉽다는 말을 포스팅 말미에 적었었지요. 이전엔 DB write 작업을 효율적으로 하기 위한 캐싱을 적용했
dooduz.tistory.com
최초 적용
application.yml에 간단한 설정을 추가해 기존 코드 변경 없이 가상 스레드를 적용해 봅니다.
spring:
threads:
virtual:
enabled: true
적용 직후 테스트 결과입니다. 기존과 동일하게 스레드 1000 x 루프 5로 상품 4종에 대한 주문을 진행했습니다.

- APDEX 0.54 → 0.37
- 전체 TPS 1150 → 620
- 쓰기 작업 TPS 110 → 62.95
- 주문 최대 응답 시간 1478ms → 6690ms
성능이 향상되지 않을 수 있다는 생각은 했지만 떨어질 거라곤 생각 못했는데 의외의 결과가 나왔습니다. 되려 플랫폼 스레드를 사용하던 때보다 더 나쁜 결과가 나온 것이었습니다. 욕심 없이 적당히 테스트만 해볼 요량이었는데 되려 성능이 떨어지고 보니 오기가 생겼습니다. 문제가 무엇인지 확인하고자 가상 스레드에 대해 좀 더 찾아보고 원인을 추측해 봤습니다.
가설 1 : CPU Bound 작업이 많다.
가설 2 : ThreadLocal 사용량이 많다.
위 가설을 토대로 Visual VM을 통해 모니터링 작업을 진행했습니다.

요청 시 CPU 사용량을 살펴보면 크게 올라가지 않고, Profile을 통해 어떤 메서드가 CPU 사용량이 높은지 추적해 봐도 그다지 큰 수치는 발견하지 못했습니다.
이 때문에 저는 가설 2가 원인이라고 거의 확신하고 있었습니다. Security Context와 Transaction 정보가 스레드 로컬에 저장되고, 가상 스레드가 캐리어 스레드에 unpark 될 때 스레드 로컬의 정보를 옮겨야 하는 경우가 생기면서 오버헤드가 발생할 것이라고 추측했습니다.
그러나 문제는 생각지 못한 곳에 있었습니다. Jmeter로 몇 번의 부하테스트를 진행한 결과 플랫폼 스레드에선 잘 작동하던 Async 메서드가 제대로 작동하지 않는 문제가 발견됐습니다. 분명 비동기 처리된 쿼리들이 모든 응답이 처리된 뒤에도 한동안 실행되고 있어야 했는데, 요청이 처리되는 것과 쿼리가 완료되는 시간이 동일한 걸 알게 된 것입니다. 비동기 처리가 제대로 되지 않으니 응답이 빠를 수가 없던 것이죠.
이에 따라 Async 어노테이션 대신 CompletableFuture의 runAsync를 사용하여 비동기 작업을 처리하도록 변경했습니다.
//@Async
@Transactional
public void updateStockAfterOrder(Long productId, Long amount){
CompletableFuture.runAsync(()->{
stockRepository.updateStockAfterOrder(productId, amount);
});
}
위 코드를 적용한 후로는 비동기 작업이 제대로 돌아가기 시작했는데, @Async를 사용할 때는 요청이 처리되면서 DB 동기화가 동시에 이루어졌다면 CompletableFuture의 경우 대부분의 요청이 처리된 후에야 DB에 Update Query 가 실행됐습니다. 둘의 동작 방식이 다소 달라 보이는데, 이에 따라 작업 실패에 대한 테스트를 할 필요가 있어 보입니다.
여하튼 위의 변경으로 문제를 하나 해결했으니 이제는 테스트를 해볼 차례입니다.

- APDEX 0.37 → 0.5x
- 전체 TPS 620 → 949
- 쓰기 작업 TPS 62 → 101
- 주문 최대 응답 시간 6690ms → 3961ms
플랫폼 스레드 사용 대비 10~20% 낮은 수준의 성능까지는 회복된 모습입니다. 그러나 여전히 수치는 다소 아쉽습니다. 다만 가상스레드 적용 후 긍정적인 점이 하나 있었는데 요청 스레드가 1000개든 2000개든 5000(!?) 개든 서버가 받아내기 시작했다는 것입니다. 이는 가상 스레드가 OS 스레드와 직접 연결되어 사용되지 않고 Heap에 생성돼서 사용되기 때문에 가능한 것으로 보입니다. Pooling으로 관리되지 않기 때문에 스레드가 몇 개가 생성되든 상관없는 것이죠.

플랫폼 스레드 사용 시 500MB를 크게 벗어나지 않던 Heap의 크기가 800MB 가까이 커진 모습입니다. 반대로 250 전후를 맴돌던 스레드 카운트는 60대에서 크게 올라가지 않습니다. 가상 스레드 몇 개가 생성되더라도 케리어 스레드는 최대 CPU 스레드까지만 늘어날 수 있기 때문에 관찰되는 특징 같습니다.
성능 개선을 통해 tomcat에서 받아낼 수 있는 동시 요청 수를 늘리는 게 목적이었는데 과정은 일치하지 않았지만 목적은 어느 정도 달성한 셈입니다. 소 뒷걸음질 치다가 쥐는 잡았으니, 다소 떨어진 성능을 잡아봐야겠습니다.
가상 스레드 사용 시 주의점을 되짚어봅시다.
상단 포스팅에 적힌 내용 일부에 의하면 MySQL은 가상 스레드 기능을 완벽하게 지원하진 않습니다. 제가 사용한 MySQL 9.0.0에선 ReentrantLock을 통해 가상스레드 호환성을 올렸다곤 하지만 정확한 성능 개선 지표가 올라온 것도 아닙니다. 따라서 단순한 select 쿼리라도 줄여보고자 이전에 캐싱한 데이터를 최대한 활용해 보기로 했습니다. 조회와 주문에 대한 캐싱 처리는 완료돼 있으니 장바구니에 상품 담는 로직까지 모두 캐싱 데이터를 사용하도록 적용해 봤습니다. 이제 주문에서 실제로 실행되는 query는 데이터 캐싱에 사용되는 최초 요청들에서 발생하는 것과, 주문 처리 후에 비동기로 실행되는 것 밖에 남지 않았습니다. 한 마디로 쿼리 없이 모든 주문 시퀀스가 끝나는 상태인 것이죠.
이후 성능 테스트입니다.
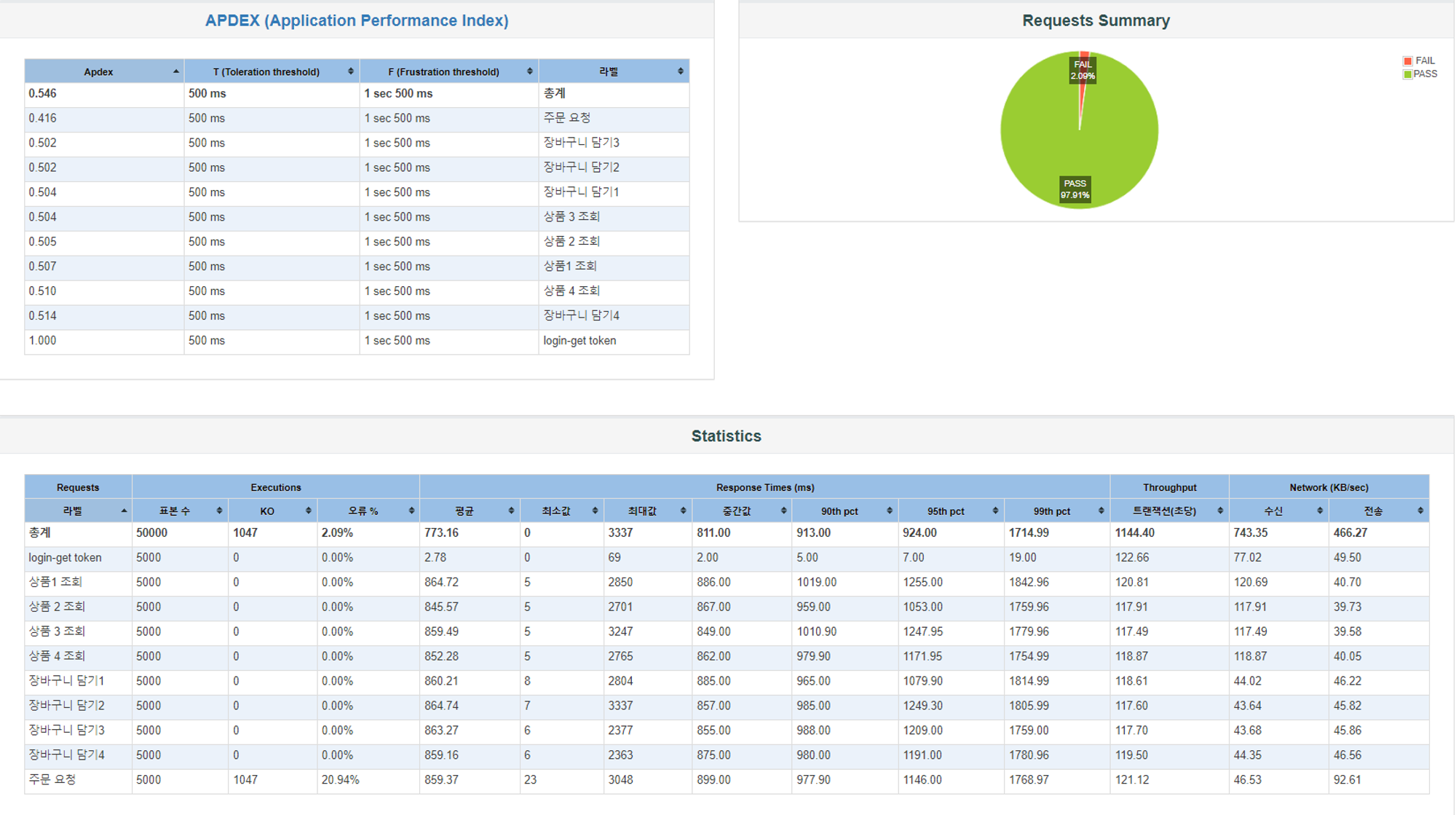
- APDEX 0.5 → 0.546
- 전체 TPS 949 → 1144
- 쓰기 작업 TPS 101 → 121
- 주문 최대 응답 시간 3961ms→ 3048ms
TPS가 플랫폼 스레드와 동일한 수준까지 올라왔습니다. 최대 응답 시간은 플랫폼 스레드의 1400ms보다 2배 이상 높은 수치를 보여주지만 이는 가상스레드의 특징 때문이라고 봐도 좋을 것 같습니다. 플랫폼 스레드의 경우 최대 스레드 수를 초과하는 요청은 Queue에 쌓이고 생성되는 스레드 수를 제한하기 때문에 CPU가 max Pool Size 만큼의 스레드에만 자원을 사용합니다. 반면에 가상 스레드는 개수가 늘어나는 만큼 자원을 모두 나눠 사용하기 때문에 평균 응답 시간이 비슷할 지언정 최대 응답 시간은 다소 느려질 수밖에 없지 않나 하는 생각입니다. 물론 이 또한 제어할 수 있는 방법이 있겠지만요.
여기까지 작업 후 기존 1000 x 5 요청에서 최초 목표였던 10000개의 스레드를 한 번에 요청하는 것으로 부하테스트 방식을 바꿔 보았습니다.


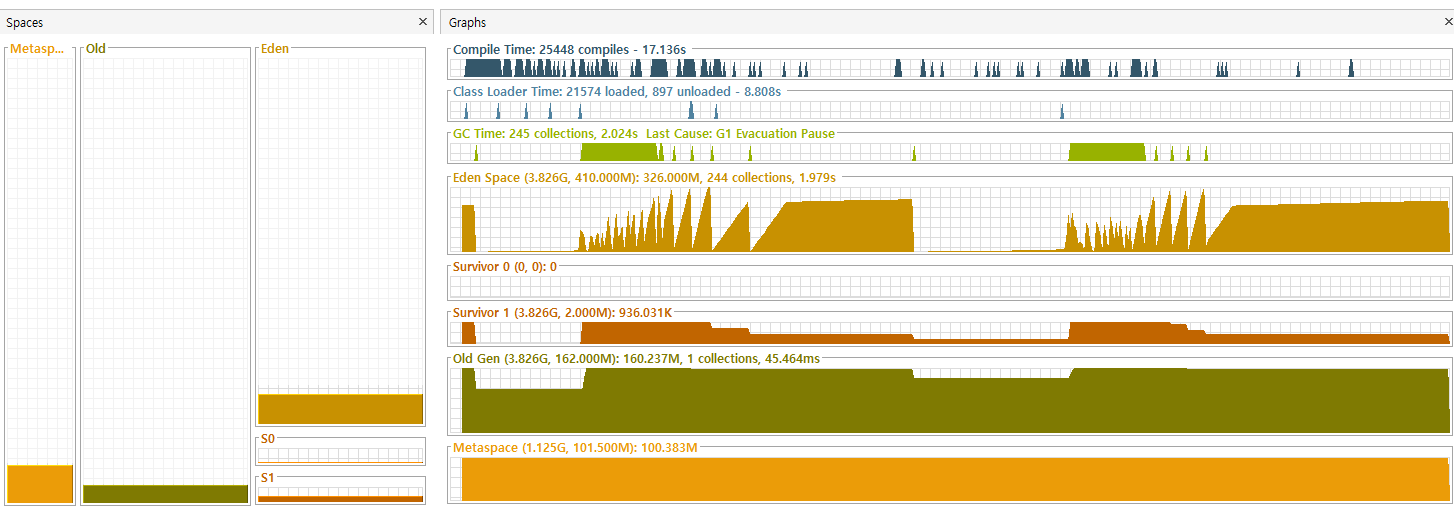
한 번에 10000건의 주문 시퀀스를 실행하고 Visual VM을 통해 모니터링한 모습입니다. 말이 1만 건이지 실제로는 로그인부터 상품 4종에 대한 조회 - 담기 - 주문까지 총 10만 건의 요청이 진행되기 때문에 무수한 가상 스레드가 생성되고 소멸되는 모습입니다. 너무 많은 수의 요청이 한 번에 들어와서 그런지 CPU Usage가 순간 26퍼센트까지 치솟기도 하고, Heap은 Max Size까지 확장되기도 했습니다. Major GC도 한 번 실행된 모습이 보이네요.
일단 지금까지 진행된 내용은 위와 같습니다. 사실 어떤 지점에서 병목이 생기고 성능 저하가 일어나는지 정확히 알 수 있었다면 좋았겠지만, Visual VM도 Virtual Thread도 모두 처음인 제겐 쉽지 않은 일이었던 것 같습니다. 어떤 추측들로 시작해서 디버깅해 보고 발견한 문제들을 하나씩 고쳐가면서 결국 목표했던 수치까지 성능이 올라오긴 했지만, 그럼에도 불구하고 더 좋은 효율을 위한 고민은 이어질 것 같습니다. 가상스레드 사용이 완전히 안정화된 것 같지도 않구요. Async와 CompletableFuture에 대한 공부도 다시 해야 하고요...
좌충우돌 우당탕탕... 가상 스레드 적용기
일단 오늘은 여기까지!
'Backend > Spring' 카테고리의 다른 글
| [예약 구매 프로젝트] Test Code (0) | 2024.07.30 |
|---|---|
| [예약 구매 프로젝트] 상품 조회 캐싱 추가 적용 - 성능 테스트 (0) | 2024.07.27 |
| [Spring Security] Session vs Token (0) | 2024.07.25 |
| [예약 구매 프로젝트] 동시 주문 요청 처리 (0) | 2024.07.24 |
| [예약 구매 프로젝트] 캐싱 전략 적용 (4) | 2024.07.23 |



